How to Scrape a Real Website with Node.js
A simple yet powerful tool for any web developer!
So you need some data. You have been searching for it and found it online. But it’s not something that you can just copy and paste because maybe you want to store it somewhere (maybe in a database or in JSON format)
But copy-pasting manually is a boring job. You are a smart guy and love to automate things.
Well, say no more! The tool you are looking for is scraping.
What is scraping anyway?
According to zyte,
Web scraping is the process of collecting structured web data in an automated fashion.
Yeah, that’s right. Today we will extract data from this website’s FAQ section.
Requirements
The concept of scraping can be broken down into the following steps.
- Get the data HTML file from the website (We will use
axios) - Parse the data (We will use
cheerio)
And that’s it! So simple right?
Initialize your project
Let’s first initialize an empty Node.js project. Go to your terminal and run the following commands
mkdir web-scrapercd web-scraper
npm init -yThis will create a package.json file for you.
Then create our root file
touch index.jsSo we have a skeleton Node.js project now. Let’s use it!
Install the dependencies
Run the following command to get the required dependencies
npm i axios cheerioOpen up your index.js file and import them
const axios = require("axios");
const cheerio = require("cheerio");Get data from the website
As we discussed earlier the first thing to do is to get the raw data from the website. That means getting the full .html file. We can do it like the following.
axios.get("https://hydeparkwinterwonderland.com/faqs/").then(
(response) => {
if (response.status === 200) {
const html = response.data;
const $ = cheerio.load(html);
}
},
(error) => console.log(err)
);Notice line number 5. We have loaded the HTML file into the cheerio . As cheerio has much resemblance with Jquery we are using the **$** as a variable name. You can use something else!.
Okay so now we have the data in the HTML format.
But how do we parse it?
To understand that we have to go to that website and open up the target website’s inspect tool. And try to understand the structure of the HTML file there.
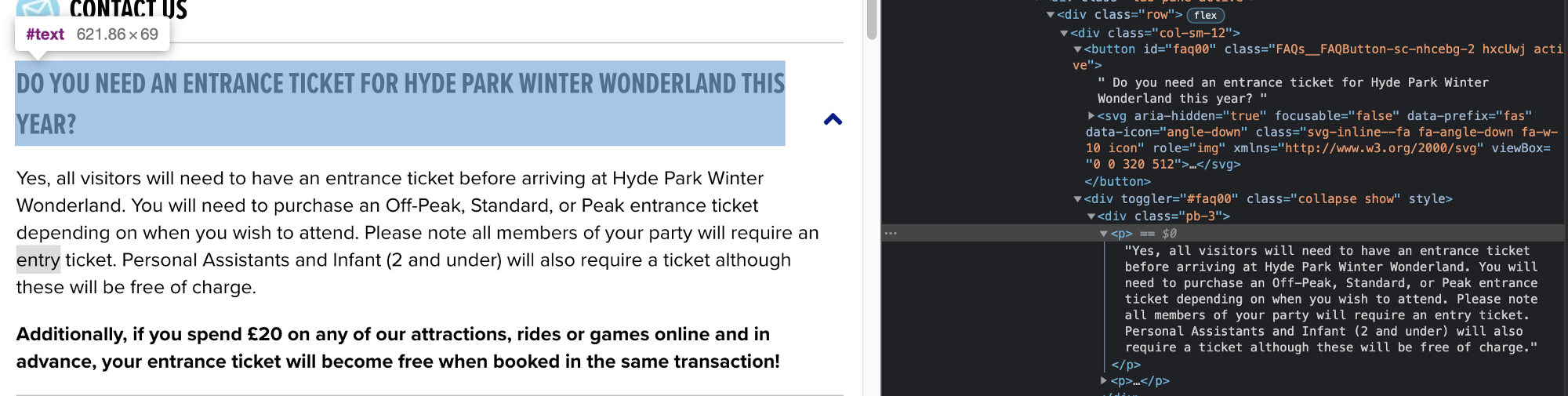
Cheerio has the ability to select based on classname or element type (div, button, etc). We will try to find out the place where we can get the questions.
Getting the questions
if we look closely the questions are inside a button which lives inside a div with classname = "row"
That means if we get all the div’s with classname="row" we will get all the faq’s and from them, we can extract the questions.
Let’s do that!
const $ = cheerio.load(html); // from the previous step
const individualBlock = $("div.row");
individualBlock.each(function (idx, el) {
const question = $(el).children("div").children("button");
console.log("question => ", $(question).text());
});After this go to your console and run
node index.jsand look at your console
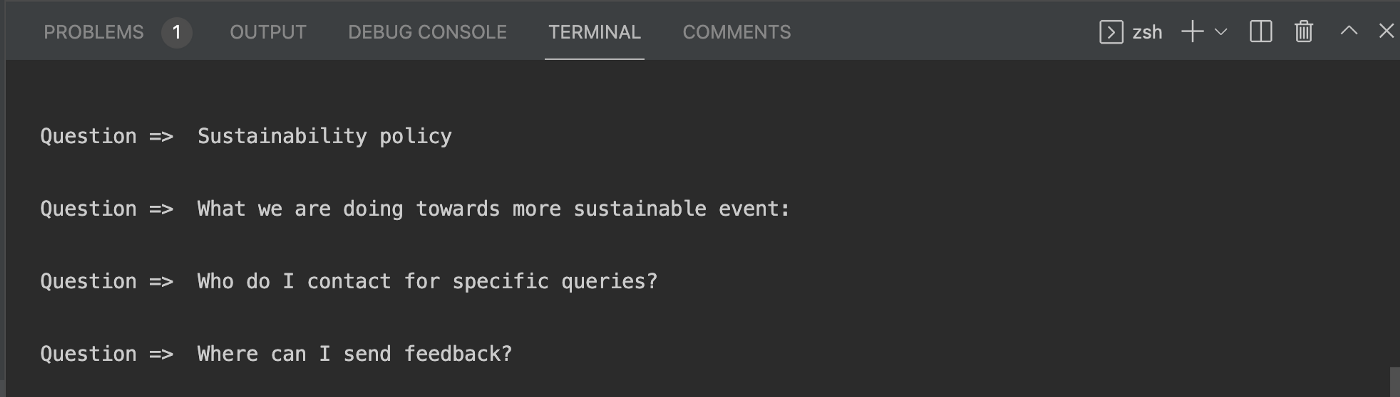
So you have scraped all the questions out of the website. Now use it any way you like. Try to figure out to get the answer’s yourself.
If you can’t you can figure out the logic to find the answers the check the complete code in the following repo.

