How to Run Queries 2600 Times Faster
Today in the era of ORM we as developers don’t have to touch the database that often. I myself built my first project without writing a single line of raw SQL inside the project.
It was working fine at first. But after some time we had some real data and the API response time was increasing.
To make the user experience better we tried to optimize our application here and there but it didn’t solve our actual problem.
It was apparent that querying the database was the bottleneck of our application. so we introduced caching which itself came with its own cost.
Today I will explain what is indexing and how we improved the performance of our application a lot.
Let’s start…
What is Indexing?
We all know a database is a large collection of data. Just like a dictionary.
From a dictionary, we can find any word really easily because the words are kept in a certain way. They are kept lexicographically(Sorted by word).

Database Indexing is exactly like that. When any new data is inserted into the database a separate table is created to organize the data according to our needs so that we can find them faster. > So Indexing helps takes a little extra time when writing data but it helps to read data faster. If your application is write heavy and don’t need to read data that often then you might not need to use indexing
Enough talk! Show me code
Okay okay, Let’s first create a table with some basic information.
STEP 1: Create a Table
The codes I am going to show you are mostly written with Postgres but other SQL languages are also very very similar.
Create TABLE EMPLOYEE (
ID INTEGER PRIMARY KEY ,
NAME VARCHAR (20),
SALARY INTEGER,
JOIN_DATE DATE
);IDis a normal unique identifier for the row.NAMEIs a StringSALARYwill hold the salary of the employeeJOIN_DATEis a date type.
STEP 2: Generate Data
Okay, now we need some data to play with. For that run the following code.
CREATE SEQUENCE employee_id_sequence
start 1
increment 1;
INSERT INTO EMPLOYEE
(ID ,NAME, SALARY, JOIN_DATE)
SELECT nextval('employee_id_sequence') ,
substr(md5(random()::text), 1, 10),
(random() * 70 + 10)::integer,
DATE '2018-01-01' + (random() * 700)::integer
FROM generate_series(1, 1000000);We won’t go into much detail about this code. All it does is generate a million random rows for us.
If you already have a table with a million data then you can use that.
Step 3: Let’s find a name
Now we will try to find a user with a specific name in our database. It’s a very common use case for all applications.
You can run the following code to do that.
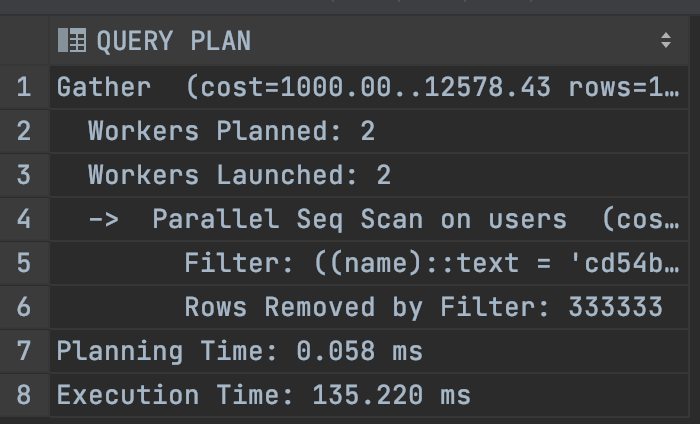
EXPLAIN ANALYSE SELECT * FROM USERS
WHERE NAME ='cd54b20d57';Note the
EXPLAIN ANALYZEpart of our query isPostgresspecific. It doesn’t actually run the query. It just analyzes the query and gives us some more information.
Let’s see the output and at the bottom, we can see that our query execution time is 135ms
STEP 4: Create an Index
Now we will create an index on the field NAME . The syntax is for Postgres but other SQL will have a similar format.
CREATE INDEX ON EMPLOYEE(NAME);It will take some time and create the index. So wait for some time.
Moment of Truth
Now we will run the previous query once again.
EXPLAIN ANALYSE SELECT * FROM USERS
WHERE NAME ='cd54b20d57';Now see the output.
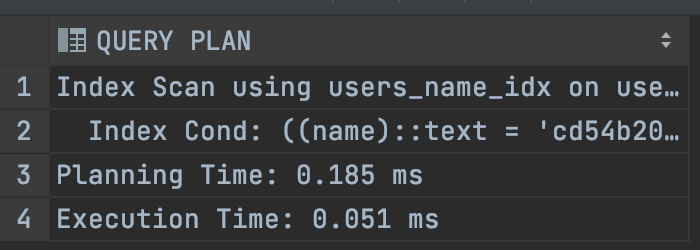
The execution time of the query has come down to 0.051 ms only!
So our query will run around 2600 times faster now. How awesome is that!
Okay great. Congratulations on making it this far. Hopefully, you noobs(like me 👊) now can understand the power of indexing.
That’s it for today. Happy Coding! :D
Get in touch with me via LinkedIn


{kind=link}